Theorie und Aufbau
Die Oracle Model Clause ist seit Version 10g verfügbar, ihre teils hohe Komplexität und die dadurch bedingte anfangs recht steile Lernkurve macht sie aber trotzdem zu einem Nischen-Feature. Im Prinzip kann man mit diesem Feature einzelne Zellen direkt ansprechen und sehr gezielt differenzierte Berechnungen anstellen. Da man mit diesem Feature allerdings auch ein enorm mächtiges Werkzeug zur Verfügung hat, soll hier im Folgenden ein kurzer Einblick gegeben werden, wie man sich langsam an die ersten Anwendungsfälle wagen kann, ohne von dem schieren Umfang and Möglichkeiten erschlagen zu werden. Dabei wird Information aus der offiziellen Oracle Dokumentation zusammengefasst und mittels anschaulicher Beispiele in praktischer Umsetzung verdeutlicht.
Lt. Doku (https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/SELECT.html#GUID-CFA006CA-6FF1-4972-821E-6996142A51C6) ist der grundlegende Aufbau der gesamten Model Clause wie folgt:
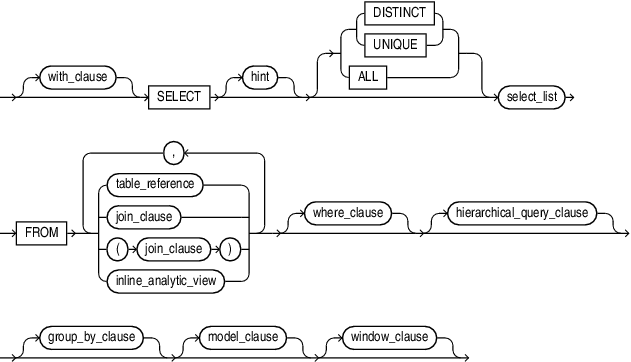
Abbildung 1: Grundlegender Aufbau SELECT
Hier sieht man nach der Group By Clause die Model Clause. Diese ist wiederum wie folgt aufgebaut:

Abbildung 2: model_clause
Hieran sieht man bereits, dass lediglich die Komponente main_model verpflichtend ist. Um den Einstieg so einfach wie möglich zu halten, betrachten wir in diesem Artikel auch nur das main_model:

Abbildung 3: main_model
Wir betrachten auch hier nur die verpflichtenden Aspekte, die model_column_clauses und die model_rules_clause:
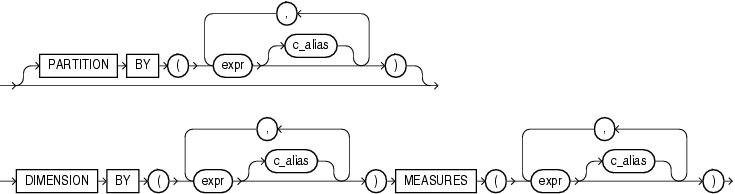
Abbildung 4: model_column_clauses
Die Model Column Clause definiert die genutzten Spalten und wie die Spalten verwendet werden. Dabei gibt es 3 Gruppen:
PARTITION BY:
Wie auch bei analytischen Funktionen kann man die Datenmenge anhand von beliebigen Spalten (und theoretisch auch Ausdrücken wie Funktionen) in Gruppen aufteilen (=partitionieren). Im Beispiel am Ende wird darauf noch genauer eingegangen. Dieser Aspekt ist optional.
DIMENSION BY:
Die Spalten der Dimension identifizieren eindeutig eine Zeile innerhalb einer Parition (falls vorhanden). Man sieht an den Keywords bereits, dass das ganze Konzept aus dem Analytics Bereich kommt.
MEASURES:
Hier werden die tatsächlichen Spalten definiert auf denen Berechnungen durchgeführt werden.
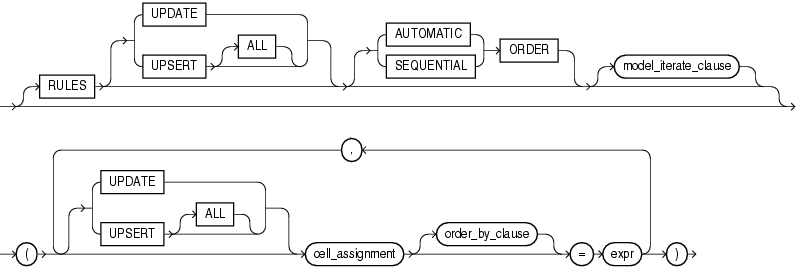
Abbildung 5: model_rules_clause
In der Model Rules Clause werden die tatsächlichen Berechnungen definiert, die im Prinzip Zuweisungen mit einer linken Seite (Ziel der Zuweisung) und einer rechten Seite (Wert der zugewiesen wird) bestehen. Der obere Bereich der Abbildung 5 ist komplett optional, daher betrachten wir erneut lediglich den unteren Bereich. Der wichtige Punkt hierbei ist cell_assignement.
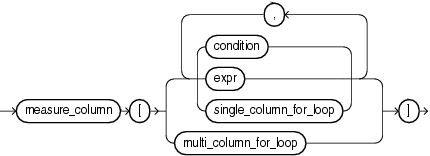
Abbildung 6: cell_assignement
Wir werden uns vorerst mal dem einfachsten Fall widmen, der direkten Identifizierung einer oder mehrerer Zellen. Wie oben bereits beschrieben, definiert die Gesamtheit der Spalten welche als Dimensionen definiert wurden eindeutig eine Zeile (innerhalb einer Partition falls vorhanden). Damit wird eine Zelle oder eine Menge an Zellen eindeutig definiert, indem die Measure Spalte definiert wird und für die Dimensionsspalten Werte angegeben werden (mehrere Zellen können angegeben werden indem beispielsweise Wildcards genutzt werden). Zur Veranschaulichung beginnen wird direkt mit einem praktischen Beispiel.
Praktisches Beispiel
Die Basis für unser praktisches Beispiel ist die Tabelle Schulnoten. Erstellskript und Testdaten können am Ende des Blogeintrags heruntergeladen werden. Der Aufbau ist wie folgt:
create table SCHULNOTEN
(
schulstufe NUMBER,
schueler VARCHAR2(255),
schuelernummer NUMBER,
klasse VARCHAR2(1),
jahr NUMBER,
fach VARCHAR2(30),
note NUMBER
)
Die Tabelle beinhaltet Schulnoten für Schüler in einer sehr vereinfachten Form. Die Testdaten beinhalten die Daten von jeweils 16 Schülern einer 3. Klasse für 3 Schulstufen sowie zwei 2. Klassen mit je 2 Schulstufen. Auf Basis dieser Daten sollen nun diverse Auswertungen durchgeführt werden. Starten wir mit einer simplen Abfrage: Für den Schüler mit der Nummer 1, für das Fach „Deutsch“, für die 4. Schulstufe im Jahr 2021 soll die voraussichtliche Note berechnet werden als gerundeter Durchschnittswert der Vorjahre. Natürlich kann man diese Berechnung auch über Aggregatsfunktionen berechnen, aber es dient als simpler Einstieg:
select schulstufe, schueler, jahr, note
from schulnoten
where schuelernummer = 1
and fach = 'Deutsch'
MODEL
DIMENSION BY(schulstufe, schueler, jahr)
MEASURES(note)
(note [ 4, 'Anton Anger', 2021 ] = round((note [ 3, 'Anton Anger', 2020 ] + note [ 2, 'Anton Anger', 2019 ] + note [ 1, 'Anton Anger', 2018 ]) / 3,0));
Hier sehen wir uns die einzelnen Komponenten an:
select schulstufe, schueler, jahr, note
from schulnoten
where schuelernummer = 1
and fach = 'Deutsch'
Das ist die grundlegende Abfrage. Wenn die Model Clause verwendet wird, müssen ALLE Spalten, die hier abgefragt werden als PARTITION, DIMENSION oder MEASURE deklariert werden. Weiters müssen hier bei Verwendung von Alias-Bezeichnungen diese angegeben werden. Das bedeutet, dass z.B. folgende Statements nicht funktionieren werden (der fehlerhafte Teil ist jeweils fett markiert):
select schulstufe, klasse, schueler, jahr, note
from schulnoten
where schuelernummer = 1
and fach = 'Deutsch'
MODEL
DIMENSION BY(schulstufe, schueler, jahr)
MEASURES(note)
(note [ 4, 'Anton Anger', 2021 ] = round((note [ 3, 'Anton Anger', 2020 ] + note [ 2, 'Anton Anger', 2019 ] + note [ 1, 'Anton Anger', 2018 ]) / 3,0));
Die Spalte Klasse wird hier in keiner der drei Kategorien angeführt und führt daher zu einem ORA-32614: unzulässiger MODEL SELECT Ausdruck.
select schulstufe, schueler, jahr, note
from schulnoten
where schuelernummer = 1
and fach = 'Deutsch'
MODEL
DIMENSION BY(schulstufe, schueler name, jahr)
MEASURES(note)
(note [ 4, 'Anton Anger', 2021 ] = round((note [ 3, 'Anton Anger', 2020 ] + note [ 2, 'Anton Anger', 2019 ] + note [ 1, 'Anton Anger', 2018 ]) / 3,0));
Hier wird in den Dimensionen der Spalte SCHUELER der Alias NAME gegeben, daher müsste auch im Select-Teil die Bezeichnung NAME verwendet werden.
Ansonsten folgt der Select-Teil dem üblichen Standard. Wir schränken die Datenmenge hier per Where Clause bereits stark ein. Damit kommen wir zum nächsten Punkt:
MODEL
DIMENSION BY(schulstufe, schueler, jahr)
MEASURES(note)
Das Keyword MODEL leitet die Model Clause ein. Da PARTITION BY optional ist und wir ohnehin auf genau einen Schüler und ein Fach einschränken erübrigt sich ihr Nutzen hier. Die Abschnitte für DIMENSION BY und MEASURES sind klar ersichtlich, wir haben also 3 Dimensionen und 1 Measure (Faktum wäre das häufig benutzte deutsche Wort dafür). Hier können für die einzelnen Spalten Alias-Bezeichnungen vergeben werden, wie im Fehlerbeispiel oben ersichtlich war. Diese Alias-Bezeichnungen sind dann durchgehend zu nutzen, auch beim nächsten und in diesem Fall letzten Abschnitt:
(note [ 4, 'Anton Anger', 2021 ] =
round((note [ 3, 'Anton Anger', 2020 ] + note [ 2, 'Anton Anger', 2019 ] + note [ 1, 'Anton Anger', 2018 ]) / 3,0));
Zur besseren Lesbarkeit wurden die linke und rechte Seite getrennt. Hier sieht man eine exakte Zuweisung zu einer Zelle auf der linken Seite (in diesem Fall, würde es mehrere Schüler mit dem exakt gleichen Namen geben würde die Zuweisung mehrere Zellen befüllen) sowie mehrere exakte Zuweisungen (oder besser Abfragen) auf der rechten. In einfachen Worten steht hier:
Addiere die Noten des angegebenen Schülers aus Stufe 3 im Jahr 2020 bzw. aus Stufe 2 im Jahr 2019 und Stufe 1 im Jahr 2018 und dividiere die Summe durch 3 – eine manuelle Durchschnittsberechnung. Da wir in diesem Select Daten erhalten die es in der Tabelle gar nicht gibt, wäre eine Umsetzung ohne Model Clause nur über Analytic Functions oder Mengenoperationen wie UNION möglich. Beides würde mehr Code benötigen.
Nun kann man den Sinn einer manuellen Durchschnittsberechnung hinterfragen, wenn Oracle dafür praktische Aggregationsfunktionen anbietet und das durchaus zu Recht. Würden wir das Statement anpassen (weil z.B. nicht von 3 sondern von mehreren 100 Zeilen der Durchschnitt berechnet werden soll) würde es wie folgt aussehen:
select schulstufe, schueler, jahr, note
from schulnoten
where schuelernummer = 1
and fach = 'Deutsch'
MODEL
DIMENSION BY(schulstufe, schueler, jahr)
MEASURES(note)
(note [ 4, 'Anton Anger', 2021 ] = round(avg(note) [ any, 'Anton Anger', jahr between 2018 and 2020 ],0));
Das wirkt gleich deutlich sauberer und einfacher. Vorsicht bei der Setzung der Klammern, die Aggregationsfunktion wird NUR um die Measure Spaltenbezeichnung gemacht, das Dimensions-Array in eckigen Klammern steht danach (wird das nicht gemacht gibt die Datenbank einen Fehler zurück: ORA-00934: Gruppenfunktion hier nicht zulässig).
Ein weiterer Aspekt hier sind der Wildcard Operator und eine Range Angabe, beides Mittel, um mehrere Zeilen auf einmal anzusprechen (was hier durch Verwendung der Aggregationsfunktion Sinn macht).
Der Wildcard Operator any bewirkt genau das was das Keyword vermuten lässt: Diese Spalte wird nicht betrachtet bei der Berechnung. Die Range-Angabe between 2018 and 2020 wiederum funktioniert exakt gleich wie eine entsprechende Where Clause.
Bevor wir die Model Clause gewinnbringender einsetzen, noch eine kurze Erklärung zur Zuweisung der Werte der Dimensionen in den Regeln. Die Beispiele bisher nutzten fast ausschließlich eine positionelle Referenz, das bedeutet die Werte stehen an der Stelle im Array an welcher in der Dimensionsdefinition die jeweilige Spalte steht.

Abbildung 7: Zuweisung der Werte der Dimensionen
Alternativ dazu kann man auch wie beim Aufruf einer PL/SQL Prozedur eine symbolische Referenz verwenden. Bei der Range-Angabe wie oben MUSS das gemacht werden. Wenn wir das nun für alle Stellen so umsetzen würde es wie folgt aussehen:
select schulstufe, schueler, jahr, note
from schulnoten
where schuelernummer = 1
and fach = 'Deutsch'
MODEL
DIMENSION BY(schulstufe, schueler, jahr)
MEASURES(note)
(note [ schulstufe=4, schueler='Anton Anger', jahr=2021 ] = round(avg(note) [ schulstufe is any, schueler='Anton Anger', jahr between 2018 and 2020 ],0));
VORSICHT: Wenn symbolische Referenzen verwendet werden, dann können keine neuen Zeilen eingefügt werden. Das oben angeführte Statement ergibt also keine neue Zeile für 2021, das gilt allerdings nur für die linke Seite, folgendes Statement funktioniert also dann wieder korrekt:
select schulstufe, schueler, jahr, note
from schulnoten
where schuelernummer = 1
and fach = 'Deutsch'
MODEL
DIMENSION BY(schulstufe, schueler, jahr)
MEASURES(note)
(note [ 4, 'Anton Anger', 2021 ] = round(avg(note) [ schulstufe is any, schueler='Anton Anger', jahr between 2018 and 2020 ],0));
So weit war alles sehr simpel und eigentlich nicht des Aufwands einer Model Clause wert. Dehnen wir das Thema aus und lassen uns für den Schüler mit Nummer 1 für alle Fächer die geschätzten Noten für das Jahr 2021 ausgeben.
select schulstufe, schueler, jahr, fach, note
from schulnoten
where schuelernummer = 1
MODEL
DIMENSION BY(schulstufe, schueler, jahr, fach)
MEASURES(note)
(note [ 4, 'Anton Anger', 2021, for fach in (select distinct fach from schulnoten) ] = round(avg(note) [ any, 'Anton Anger', jahr between 2018 and 2020 , cv(fach)],0))
order by 1,4;
Um alle Fächer zu berechnen, muss eine Schleife genutzt werden, das ist dieser Teil:
for fach in (select distinct fach from schulnoten)
Grundsätzlich könnte auch der Any Operator genutzt werden, aber dann gibt die Abfrage nur Zeilen zurück, welche bereits existieren, ich könnte also nur die Noten aus den Jahren 2018 – 2020 berechnen lassen aber keine neuen Zeilen für 2021. Aus diesem Grund muss das ganze über eine Schleife gemacht werden. In diesem Zusammenhang ist dann auch noch folgender Operator wichtig:
cv(fach)
Der CV() Operator gibt den Current-Value, den aktuellen Wert zurück. Im Rahmen dieser Schleife gibt er also bei jedem Durchlauf den Wert des Durchlaufs zurück. Mit diesen beiden Informationen können wir nun für alle Schüler und Fächer der Klasse die neuen Noten berechnen.
select schulstufe, schueler, jahr, fach, note
from schulnoten
where schuelernummer in (select schuelernummer from schulnoten where schulstufe = 3)
MODEL
DIMENSION BY(schulstufe, schueler, jahr, fach)
MEASURES(note)
(note [ 4, for schueler in (select distinct schueler from schulnoten), 2021, for fach in (select distinct fach from schulnoten) ] = round(avg(note) [ any, cv(schueler), jahr between 2018 and 2020 , cv(fach)],0))
order by 1,2,4;
An diesem Beispiel erkennt man auch gut, dass die Model Clause nur auf Daten zugreifen kann, welche auf Basis der Where-Bedingung existieren. Würde man die Where Clause statt mit einer IN Clause mit einem direkten Filter auf die Schulstufe machen, würde man nur Daten für Schulstufe 3 und 4 erhalten und der Durchschnittswert basiert nur auf den Werten aus Schulstufe 3.
Soweit können wir nun für alle Fächer für jeden Schüler einer bestimmten Klasse/Schulstufe eine simple Voraussage der Noten in der nächsten Schulstufe abfragen. Idealerweise können wir das allerdings für jeden Schüler, unabhängig von der Schulstufe für jedes Fach. Das wäre der gewünschte Endzustand. Ein mögliches Statement dafür könnte wie folgt aussehen:
select schuelernummer,schulstufe, schueler, klasse, jahr, fach, note
from schulnoten
MODEL
PARTITION BY(schuelernummer, schueler, klasse)
DIMENSION BY(jahr, fach)
MEASURES(schulstufe,note)
(note [ 2021, for fach in (select distinct fach from schulnoten) ] = round(avg(note) [ jahr between 2018 and 2020 , cv(fach)],0),
schulstufe [ 2021, for fach in (select distinct fach from schulnoten) ] = max(schulstufe) [ jahr between 2018 and 2020 , cv(fach)] + 1)
order by 2,5,3,6;
Da sinnvollerweise auch Daten zu den Schulstufen der jeweiligen Jahre vorhanden sein sollen und diese aber nicht mehr hartcodiert übergeben werden können ist die Schulstufe in die Measures verschoben würden. Zusätzlich werden die Daten mittels PARTITION BY nach Schüler aufgeteilt, das hat den simplen Grund, dass die Noten immer nur in Abhängigkeit der Noten des jeweiligen Schülers berechnet werden, das erspart auch mühsame Arbeit bei der Dimensionsdefinition. Die Klasse ist kein echtes Partitionierungskriterium, da sie aber ausgegeben werden soll kann sie problemlos hier mit eingetragen werden. Für die Schulstufe wird eine neue Regel erfasst, welche den Maximalwert des jeweiligen Schülers für den jeweiligen Zeitraum berechnet und um eins erhöht. Da wird genau genommen auch jedes Fach für sich betrachten könnten wir hier aber auch einfach das Fach von den Dimensionen in die Partition Clause schieben und sparen uns damit die For Schleife, das würde dann so aussehen:
select schuelernummer, schulstufe, schueler, klasse, jahr, fach, note
from schulnoten
MODEL
PARTITION BY(schuelernummer, schueler, klasse, fach)
DIMENSION BY(jahr)
MEASURES(schulstufe,note)
(note [ 2021 ] = round(avg(note) [ jahr between 2018 and 2020 ],0),
schulstufe [ 2021 ] = max(schulstufe) [ jahr between 2018 and 2020 ] + 1)
order by 2,5,3,6;
Nochmal etwas simpler, denn genau genommen ist das Jahr die einzige Variable die wir hartcodiert setzen.
Einen letzten Fall sehen wir uns noch an. Die Kinder bekommen in der 4. Schulstufe statt Sachunterricht die beiden Fächer Biologie und Physik. Die Note für Biologie soll sich aus zu je 50% aus den Noten der Fächer Deutsch und Sachunterricht der 3. Schulstufe berechnen, die Note für Physik zu je 50% aus den Noten der Fächer Mathematik und Sachunterricht der 3. Schulstufe. Wir betrachten also nur die Schüler der 3. Schulstufe in diesem Fall. Das Statement dafür könnte man zum Beispiel wie folgt strukturieren.
select schulstufe, schueler, jahr, fach, note
from schulnoten
where schuelernummer in (select schuelernummer from schulnoten where schulstufe = 3)
MODEL
PARTITION BY(schueler)
DIMENSION BY(schulstufe, jahr, fach)
MEASURES(note)
(note [ 4, 2021, for fach in (select distinct fach from schulnoten where fach <> 'Sachunterricht') ] = round(avg(note) [ any, jahr between 2018 and 2020 , cv(fach)],0),
note [ 4, 2021, 'Biologie' ] = round(( note[ 3, 2020, 'Sachunterricht' ] + note[ 3, 2020, 'Deutsch' ] ) / 2,0),
note [ 4, 2021, 'Physik' ] = round(( note[ 3, 2020, 'Sachunterricht' ] + note[ 3, 2020, 'Mathematik' ] ) / 2,0))
order by 1,2,4;
Eine Kombination des vorigen mit diesem Statement ist nicht möglich, da die Schulstufe einmal als Dimension herangezogen wird und einmal als Measure berechnet wird. In diesem Fall kann ich also nur einen von beiden Fällen innerhalb einer Model Clause abdecken.
Wie bereits eingangs erwähnt, wurden in diesem Artikel lediglich die grundlegenden Funktionen der Model Clause abgedeckt. Weitere Artikel, welche die zusätzlichen Möglichkeiten erklären, werden folgen.