Oracle Active Dataguard and Cloning of PDBs – the easy way
In diesem Artikel werden wir mehrere Features der 12.1.0.2 Datenbank beschreiben.
Active Data Guard, ein kostenpflichtiges Feature um Reporting auf die Standby Seite zu bringen (und tolle Administrationsfeatures beinhaltet, wie z. B. vereinfachtes Cloning (wie im Artikel beschrieben) oder Global Data Services).
Multitenant, ein Feature, das man für Datenbank-Konsolidierung benutzt und neue Möglichkeiten zur Administration anbietet.
PDB Cloning in einem ADG Environment: Clones kann man als eine Art von Backup sehen, wenn man Applikation Upgrades oder irgendwelche invasiven Tätigkeiten durchführt und einen schnellen Fallback haben möchte.
In höheren Versionen gibt es bessere Möglichkeiten, wie Flashback PDB oder PDB PITR.
Dieser Artikel dient zur Verbesserung des Daily Business, um Kunden zufriedener machen zu können. Wenn man schon Lizenzen besitzt, sollte man auch die zur Verfügung stehenden Features benutzen, nicht wahr?
Manche unserer Kunden haben Multitenant und Active Data Guard lizensiert, wobei man Multitenant sehr selten für Cloning oder verschiedene andere Tätigkeiten benutzt. Es ist auch klar, weshalb dies so ist, denn viele Kunden kennen diese Features nicht. Es gehört zu unseren Aufgaben, unseren Kunden diese Features vorzustellen und deren Einsatzgebiete zu erklären. Ein glücklicher Kunde ist der beste Kunde.
Bis vor kurzen war es so, dass wir entweder Restore Points erstellt haben, die in Wahrheit in einem 12.1.0.2 CDB Environment nicht wirklich benutzbar sind, denn man kann nur den ganzen Container zurückspielen oder wir mussten Duplicates (Restore) erstellen, was Zeit beanspruchte und unnötige Downtime verursachte. Da wir gern diese Tätigkeiten optimieren, ist es nötig Kunden zu informieren wie man es in Zukunft machen könnte, damit die Projekte weitergehen und jeder zufrieden ist.
Dieses Dokument beschreibt die Möglichkeiten, die sehr einfach sind, wenig Zeit kosten, nur freien Storage und einen DBA brauchen, der diese Features kennt.
Active Data Guard erlaubt es den Kunden das Reporting auf die Disaster Systeme zu schwenken, damit die Performance der Produktivsysteme, bei performance-lastigen Reports, nicht beeinträchtigt wird. Es ermöglicht uns weiterhin die Dinge zu tun, die schnell sind, Downtimes vermeiden und Service Agreements leicht erfüllen.
Wenn man in einem Active Data Guard Environment eine lokale PDB klont, werden die Standby PDBs automatisch erstellt und in einer 12.1.0.2 sind dazu nur 5 Kommandos notwendig (denn man muss die PSORGER PDB wieder READ WRITE öffnen).
In höheren Versionen kann man einen Hot Clone erstellen, wenn man Local Undo benutzt, das heißt Zero Downtime.
SYS@CDB1 SQL> alter pluggable database psorger close immediate instances=all ; Pluggable database altered. SYS@CDB1 SQL> alter pluggable database psorger open read only instances=all ; Pluggable database altered. SYS@CDB1 SQL> create pluggable database psorgerc from psorger ; Pluggable database created. [oracle@exa2vm01 ~]$ tail -f $al Mem# 0: +DATAX6C1/E2CDB1/ONLINELOG/group_22.2191.970881745 Mem# 1: +RECOX6C1/E2CDB1/ONLINELOG/group_22.9224.970881745 1: +RECOX6C1/E2CDB1/ONLINELOG/group_22.9224.970881745 Thu Sep 10 20:36:27 2020 Recovery created pluggable database PSORGERC Thu Sep 10 20:36:54 2020 Recovery copied files for tablespace SYSTEM Recovery successfully copied file +DATAX6C1/E2CDB1/AEFAD6D19935CDF7E0537D001BAC3B4F/DATAFILE/system.2920.1050784587 from +DATAX6C1/E2CDB1/647EDCDA7FB28F8DE0538B001BACEE69/DATAFILE/system.1628.967329427 Datafile 23 added to flashback set Successfully added datafile 23 to media recovery Datafile #23: '+DATAX6C1/E2CDB1/AEFAD6D19935CDF7E0537D001BAC3B4F/DATAFILE/system.2920.1050784587' Thu Sep 10 20:37:23 2020 Recovery copied files for tablespace SYSAUX Recovery successfully copied file +DATAX6C1/E2CDB1/AEFAD6D19935CDF7E0537D001BAC3B4F/DATAFILE/sysaux.2929.1050784615 from +DATAX6C1/E2CDB1/647EDCDA7FB28F8DE0538B001BACEE69/DATAFILE/sysaux.1629.967329427 Datafile 24 added to flashback set
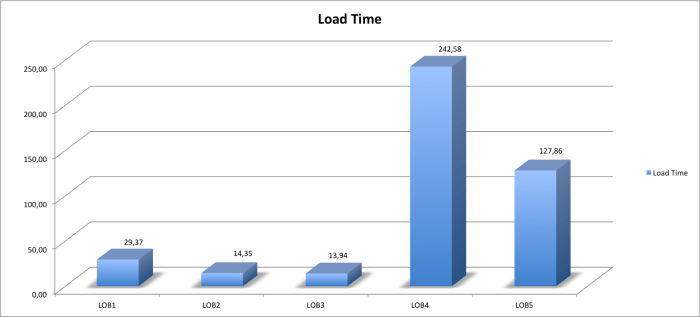
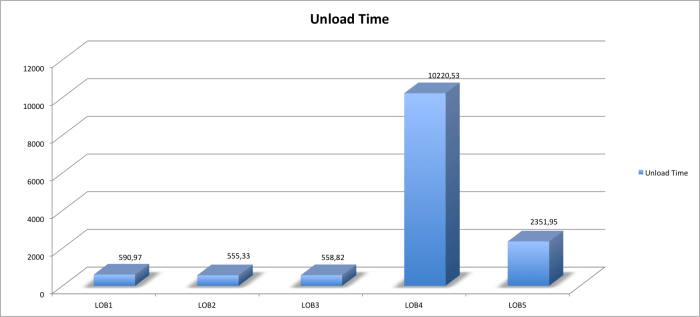
Wie man sieht reichen 3 Kommandos aus, um eine Pluggable Database zu klonen (EE 12.1.0.2 mit ADG). Eine 100GB Datenbank kann auf einer Exadata in wenigen Minuten geklont werden und somit verfügt man über eine „Point in Time“ Kopie der PDB, die man im Fall eines schnellen „Restores“ wieder benutzen kann. Es handelt sich hierbei nicht um einen Restore, aus Kundensicht sieht es jedoch so aus, als würde man etwas aus der Vergangenheit zurückbringen. Letztendlich wird hierbei nur ein mächtiges Feature der Enterprise Edition von Oracle genutzt.
Natürlich gibt es aber auch Situationen, in denen ein Restore erforderlich wird, da keine Clones erstellt wurden. In diesem Fall ist es am besten einen DUPLICATE vom Backup zu erzeugen. Dies ist einfach umzusetzen, braucht nur wenige Kommandos und ist automatisiert, so dass der DBA wenig Zeit mit der Kommandoeingabe verliert. Mehr Informationen zu diesem Thema folgen in einem weiteren Artikel.
Jetzt werden wir uns aber dem Thema cloning weiter widmen und zeigen in wenigen Kommandos, wie wir aus dem Duplikat die Pluggable Database wieder in den korrekten Container einfügen können.
Das Scenario beinhaltet:
1x Active Data Guard Configuration (12.1.0.2.200114) – CDB1 mit mehreren PDBs, PDB1, PDB2, PDB3
1x Duplikat der CDB Point in Time Recovered (12.1.0.2.200114) – CDBDUP mit PDB1
Die technischen Schritte um die PDB1 aus der CDBDUP in die CDB1 zu kopieren sind folgende:
1. In der CDB1 löschen wir die PDB1
alter pluggable database pdb1 close immediate instances=all ; drop pluggable database pdb1 including datafiles ;
2. In der CDBDUP der PDB1 erstellen wir einen Benutzer mit Berechtigungen zum Klonen
ALTER SESSION SET CONTAINER=pdb1 ; CREATE USER remote_clone_user IDENTIFIED BY remote_clone_user; GRANT CREATE SESSION, CREATE PLUGGABLE DATABASE TO remote_clone_user;
3. In den tnsnames.ora beider DB Systeme definieren wir einen Connect String der im Scenario benutzt wird. Es ist gut nicht produktive Connect Strings zu benutzen, so weiß man zu 100% wo man sich einloggt
PDB1_PS=(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=dbhost)(PORT=1521))(CONNECT_DATA=(SID=CDBDUP)(SERVICE_NAME=pdb1)(INSTANCE_NAME=CDBDUP)))
4. In der CDB1 auf der Standby Seite setzen wir einen Parameter damit die PDB automatisch in das Standby Environment kopiert wird.
alter system set standby_pdb_source_file_dblink='pdb1_ps' ;
5. In der CDBDUP setzen wir die PDB1 in READ ONLY Modus (nach Duplicate ist die DB im MOUNT Zustand, in höheren Versionen ist diese Read Only Restriction nicht mehr da, da könnte man dann einen Relocate zB. machen)
alter pluggable database PDB1 open read only ;
6. In der CDB1 erstellen wir einen Database Link zu der PDB1 im CDBDUP
create database link pdb1_ps connect to remote_clone_user identified by remote_clone_user using 'pdb1_ps' ;
7. Wir erstellen einen Klon der PDB in der CDB1 und warten bis es fertig wird. Auf einer Exadata X6-2 dauerte eine 110GB PDB 10 Minuten. Im Background wird der Database Link für den Klon auf die Standby Seite benutzt.
create pluggable database PDB1 from pdb1@pdb1_ps ;
8. Wir öffnen die PDB1 und sind mit der Bereitstellung der PDB1 fertig. Wir öffnen die PDB mit dem Application Service damit es auf den korrekten Instanzen startet (im RAC kann es 1 Node sein oder auch 10)
alter pluggable database PDB1 close immediate instances=all ;
srvctl start service -db CDB1 -pdb pdb1_svc
Somit haben wir die PDB1 wieder in Betrieb genommen und die Welt ist für heute gerettet.
In einem Data Guard Environment geht es leider nicht so einfach, man muss manuell die Datafiles auf die Standby Seite transferieren. Um mehr Informationen darüber zu erfahren bitte den Oracle Note durchlesen.
Using standby_pdb_source_file_dblink and standby_pdb_source_file_directory to Maintain Standby Databases when Performing PDB Remote Clones or Plugins (Doc ID 2274735.1)