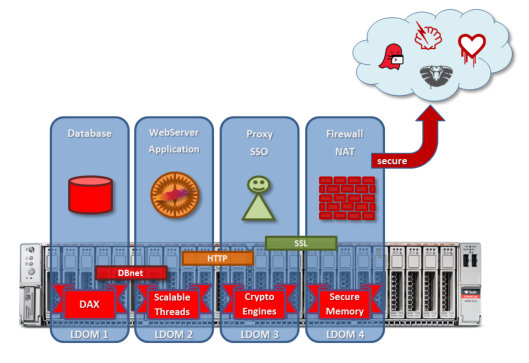
Im September war es wieder soweit, die Hausmesse von Oracle fand in San Francisco statt. Mit einer Teilnehmerzahl von ca. 60.000 und einem geschätzten monetären Einfluß auf die Bay Area von 120 Mio. $ war es wieder ein Event der Superlative.
Unser Kollege war live vor Ort und hat viele Eindrücke mitgebracht.
Sollte bis zu diesem Zeitpunkt noch irgendwer Zweifel an der strategischen Ausrichtung von Oracle gehabt haben, so sprachen die Plakate am Moscone Center eine deutliche Sprache wo es hingehen wird.

Cloud – Cloud – Cloud in vielen Ausprägungen
Der Hauptkonkurrent in diesem Umfeld ist laut Larry Ellison die Amazon Cloud, welchen man aber „Dank der 2nd Generation Hardware um ein Vielfaches abgehängt hätte“.
Glaubt man dem CEO Mark Hurd so sollen in einigen Jahren 100% der Testdatenbanken in der Cloud laufen und firmeneigene Rechenzentren um 80% zurückgehen.
Insbesondere mit dem Produkt Exadata Express Cloud Service für 175 $ pro Monat soll den Entwicklern die Public Cloud schmackhaft gemacht werden. Das Paket enthält eine OCPU (= 1 Kern) als PDB (plugable database) auf einer Exadata. Die Datenbank ist eine Enterprise Edition mit allen verfügbaren Optionen.
Ein ganz großes Thema war dieses Jahr die Infrastructure Cloud, die in einer Vielzahl an Compute und Storage Varianten angeboten wird.

Die Datenbank in die Cloud zu geben (mittels PaaS Angebot) und den Application Server oder andere Infrastruktur On Premise zu belassen, war einerseits durch die steigende Komplexität der Integration und auch durch die Latenzprobleme für viele Kunden keine Lösung.
Oracle hat das erkannt und bietet nun ein Komplettpaket im IaaS Bereich an, das von Bare-Metal bis Engineered Systeme und von Local NVMe bis Storage Cloud Software Appliance reicht.

Wer trotzdem nicht die Grenzen seines Rechenzentrums verlassen will, für den bietet Oracle „Cloud on Premise“ an.
Das erste Angebot umfasst:
- die Oracle Cloud Machine (eine Oracle Exalogic)
- die Oracle Exadata Cloud Machine
- die Oracle BIG Data Cloud Machine
Man kann erwarten, dass hier mit Sicherheit noch weitere Angebote folgen werden.
Choose your Cloud

„Choose your Cloud“ war auch die Überschrift der ausgestellten Hardware.
Im System Bereich hat Oracle bereits vorher, während und kurz nach der Open World 2016 einige Systeme angekündigt bzw. verfügbar gemacht, die sicher zu einer weiteren Verbreitung von Oracle im Hardwarebereich beitragen.
Der X86 Bereich
Die Oracle Database Appliance als kleinstes Engineered System litt immer unter der Vorgabe nur Enterprise Edition betreiben zu dürfen.
Seit Juni gibt es nun zwei neue Systeme mit 1HE (mit 1 oder 2 Prozessoren), einer 2HE Maschine mit zusätzlichem Storage und die X6-2 HA, der Nachfolger der bisherigen ODA.

ODA X6-2M und ODA X6-2L
Während die ODA X6-2M und S mit SE1, SE2, SE und EE betrieben werden können, wird die X6-2 HA weiterhin nur mit Enterprise Edition betreibbar sein.
Vor ein paar Tagen wurde auch bekannt gegeben, dass die ODA X6-2L (eine 2M mit mehr Storage) auch mit Standard Edition betreibbar ist.
Der SPARC Bereich
Nachdem im Sommer 2016 der auf 8 Prozessorkerne verkleinerte S7 Prozessor als kleiner Bruder des M7 Prozessors präsentiert wurde, folgten auf der Open World die ersten Systeme.
Der MiniCluster kann als Sparc/Solaris Pendant zur ODA X6-2 HA verstanden werden. Zwei S7-2 Dual Socket Sparc Server mit S7 Prozessor, 16,8 TB Flash und 48TB Harddisk Kapazität. Mit einem Listenpreis von $ 129.000 wird dieses Engineered System sicher auf entsprechende Nachfrage stoßen.
Exadata Database Machine SL6
Ein weiteres interessantes Engineered System, welches man aber noch nicht erwerben kann, ist die Exadata SL6.
Dieses Exadata System soll statt x86 Compute Nodes mit T7-2 Sparc Servern ausgestattet sein, aber weiterhin auf Oracle Linux betrieben werden.