Ein sehr mächtiges und effizientes Konstrukt gibt es seit der Oracle Version 12C: MATCH_RECOGNIZE. Vereinfacht gesagt lassen sich mit MATCH_RECOGNIZE regular expressions auf Zeilen anwenden, um so bestimmte Muster zu erkennen. Beispielsweise lassen sich somit in der Finanzwelt bestimmte Aktienkurs-Verläufe erkennen. Dieser Blogbeitrag soll dazu dienen, sich diesem Thema anhand einfacher und fiktiver Beispiele langsam anzunähern.
Grundlegender Aufbau:

PATTERN_PARTITION_CLAUSE
Diese ist optional. Hier kann man die Daten sortieren (ORDER BY) und in Gruppen aufteilen (PARTITION BY). Um bei jeder Ausführung der Query konsistente Ergebnisse zu erhalten, sollte zumindest ein ORDER BY eingebaut werden.
PATTERN_MEASURES_CLAUSE
Dieser Abschnitt definiert die Spalten, welche im SELECT Teil ausgegeben werden. Es gibt einige inbuilt functions, welche hier verwendet werden können. Dazu später mehr.
PATTERN_DEF_DUR_CLAUSE
Hier wird die eigentliche magic definiert. In diesem Abschnitt werden die patterns definiert, welche über jede Zeile ausgeführt werden. Gibt es ein match, sprich wird genau dieses Muster identifiziert, wird die Zeile ausgegeben.
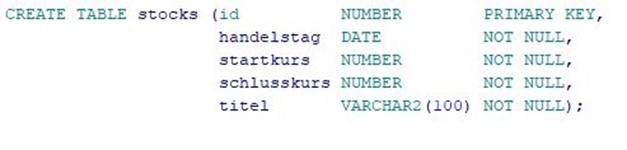
Wir schauen uns anhand einiger Beispiele die einzelnen Abschnitte näher an. Zu diesem Zwecke habe ich eine Tabelle mit Aktiendaten erstellt, welche wie folgt definiert ist (Das Skript kann am Ende des Artikels heruntergeladen werden):
Die Tabelle beinhaltet Aktienkurse eines fiktiven Unternehmens. Wir starten mit einer simplen Abfrage, anhand welcher ich auf die Struktur näher eingehen möchte: Alle Handelstage, an denen es einen oder mehrere Handelstage gibt, welche einen Startkurs größer als 17 haben:

Nachfolgend eine Erklärung der einzelnen Codeteile:
PARTITION BY: Unterteilt die Daten je nach Titel in einzelne Gruppen. In unserem Fall haben wir nur einen Titel in unseren Testdaten, wodurch es sowieso nur eine Gruppe gibt, nämlich die der „Datenbank AG“.
ORDER BY: Sortiert die Daten in der jeweiligen Gruppe je nach Handelstag aufsteigend.
MEASURES: Definiert, welche Spalten im result set zusätzlich ausgegeben werden. Hier sehen zwei inbuilt functions: CLASSIFIER() und MATCH_NUMBER(). CLASSIFIER () gibt an, welche pattern variable für diese Zeile gematched hat. MATCH_NUMBER () vergibt für gematchte Gruppe eine eigene Nummer, welche bei 1 startet und sich für jede neue Gruppe um 1 erhöht.
ALL ROWS PER MATCH: Definiert, dass bei aufeinanderfolgenden matches jede Zeile ausgegeben wird. Das pendant dazu wäre ONE ROW PER MATCH, welches auch der Default Wert ist. Hier wird dann nur die erste Zeile der jeweiligen Gruppe ausgegeben. In unserem Beispiel sehen wir, dass für Gruppe 4 jede einzelne Zeile ausgegeben wird; würden wir stattdessen ONE ROW PER MATCH verwenden, würden wir für Gruppe 4 nur die erste Zeile sehen. Das Ganze hat dann auch Auswirkungen auf die oberen drei Bereiche: Bei ALL ROWS PER MATCH, so wie wir es verwenden, könnte ich den den PARTITION BY, ORDER BY und MEASURES Bereich ganz weglassen, da sowieso alle Spalten im result set ausgegeben werden. Verwende ich hingegen ONE ROW PER MATCH, muss ich entweder Spalten im MEASURES Bereich angeben und/oder die ORDER BY / PARTITION BY Klausel angeben. Das Prinzip ist dem GROUP BY also sehr ähnlich.
PATTERN: Hier liste ich die einzelnen Variablen auf, welche im DEFINE Bereich definiert sind und auf die jeweilige Zeile zutreffen müssen. In unserem Beispiel ist das die Variable „start_1“ mit einem regular expression chracter „+“. Dies bedeutet, dass es einen oder mehrere Handelstage geben muss, an denen der Startkurs höher als 17 ist.
DEFINE: Hier werden die Variablen mit ihren conditions definiert, welche im PATTERN Bereich verwendet werden können.
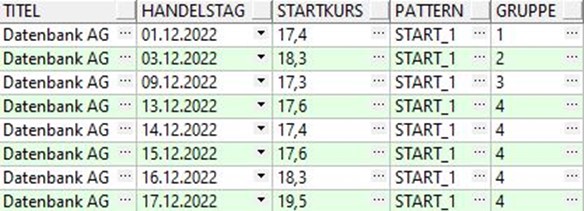
Wie können wir das Ergebnis interpretieren?
Auf die Handelstage 01.12.2022, 03.12.2022 und 09.12.2022 folgen jeweils Tage, an denen der Startkurs kleiner als 17 ist. Der 13.12. ist der erste Tag einer Reihe von Handelstagen, wo der Startkurs höher als 17 ist.
Im nächsten Beispiel wollen wir alle Handelstage ausgeben, an denen exakt zwei Mal in Folge der Startkurs höher ist als der Schlusskurs am Vortag.

Hier sehen wir, dass das SQL im Prinzip ähnlich aufgebaut ist als im Beispiel eins. Im DEFINE Bereich ist unsere pattern Variable mit der dazugehörigen condition definiert. Diese besagt, dass der Startkurs der jeweiligen Zeile höher sein muss als der Schlusskurs der darüberliegenden Zeile. Hierzu verwende ich die Funktion PREV(), welche dann genau auf die darüberliegende Zeile verweist. An diesem Beispiel sehen wir auch, dass es Sinn macht, die Daten zu sortieren, da wir nicht immer wissen, in welcher Reihenfolge die Daten aus der Datenbank abgefragt werden (das Ergebnis ist also nicht deterministisch). Im PATTERN Bereich holen wir uns die Variable und wandeln diese nun mit „{2}“ zu einem regulären Ausdruck um. Dies bedeutet, dass wir zwei Handelstage in Folge haben wollen, auf welche die condition zutrifft. Zur Kontrolle definieren wir im MEASURES Bereich die Spalte „schlusskurs_vortag“. Da MATCH_RECOGNIZE wie eine INLINE VIEW zuerst ausgeführt wird, können wir diese im SELECT Teil verwenden und ausgeben.
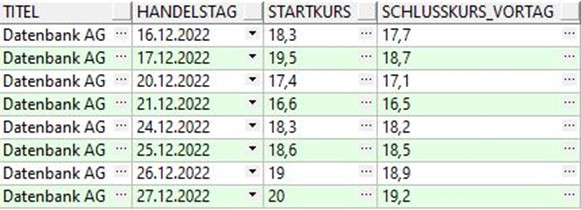
Wie können wir das Ergebnis interpretieren?
Wir sehen nun immer zwei Handelstage in Folge, an denen der Startkurs höher ist als der Schlusskurs am Vortag.
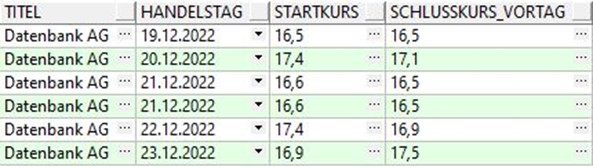
Für das nächste Beispiel überlegen wir uns folgendes Muster: An Handelstag eins soll der Startkurs zwischen 16 und 17 sein, an Handelstag zwei soll der Startkurs größer als 17 sein, an Handelstag drei soll der Startkurs wieder zwischen 16 und 17 sein.

Dieses SQL enthält eine Erweiterung, nämlich AFTER MATCH SKIP TO LAST. Diese Syntax bedeutet, dass wenn es ein match gibt, die Suche nach einem neuen Match bei der letzten pattern Variable beginnt.
Wie können wir das Ergebnis interpretieren?
Wir sehen nun alle Handelstage, die genau unserem Muster entsprechen. Würden wir AFTER MATCH SKIP TO LAST weglassen, würden nur die ersten drei Handelstage im result set erscheinen, da die Suche erst am 22.12.2022 weitergehen würde.
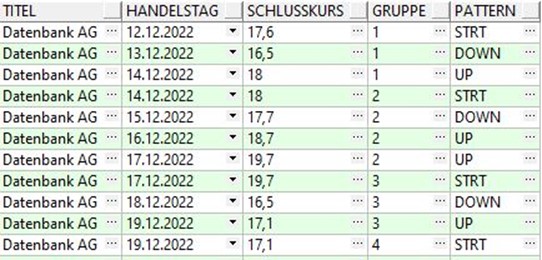
In unserem letzten Beispiel wollen wir eine typische V-Formation erkennen. Dies bedeutet, dass der Aktienkurs zunächst einbricht und sich nach Erreichen der Talsohle wieder erholt.

Hier haben wir im DEFINE Bereich drei pattern Variablen definiert, wobei man die Definition der ersten Variable „strt“ auch weglassen könnte, da sie sowieso jede Zeile matched. Diese dient für uns lediglich als Einstiegspunkt in unsere Mustersuche.
Wie können wir das Ergebnis interpretieren?
Wir sehen in unserem result set anhand der Gruppennummer, welche Handelstage eine V-Formation bilden und somit zu einer Gruppe gehören. Das Ende der jeweiligen V-Formation ist zugelich der Beginn einer neuen Kursbewegung nach unten.
Wir haben uns nun anhand einiger Beispiel angesehen, was MATCH_RECOGNIZE ist und was für Abfragen wir damit durchführen können.

 DBConcepts
DBConcepts 








 sabine klimpt
sabine klimpt